1. Elasticsearch Cluster Node
-
Master-eligible node(Master node)
- Cluster - Node - Shard 의 mapping 정보를 담고있는 node로 , index의 생성이나 삭제, 노드 추적등 전반적인 클러스터 전체에 걸친 간단한 작업을 담당- SPOF 를 위하여 "node.master : true "로 설정되어 있는 Node 중 Master 를 선출 하며, Master 장애시 재선출을 진행- "node.master : true "로 설정 하며, 기본 값은 true 로 설정split brain 방지
Master node들의 split brain을 방지하고자 "discovery.zen.minimum_master_nodes" 지시자 를 설정 해야 한다.(기본값 1)"(Master 를 구성 할 수 있는 node(node.master:true) /2)+1" 의 방식으로 설정 해야 한다.e.g) Master+data 4대 , data 5대 일 경우 (4/2)+1로 3으로 지정해야 한다. -
Data node
- 실제로 Data 가 저장 되는 Node로 Indexing 및 검색 작업이 수행- "node.data : true"로 설정 하며, 기본 값은 true 로 설정 -
Ingest node
- logstash 없이, logstash 와 같은 전처리 과정이 필요할 때 사용하는 Node- "node.ingest : true "로 설정 하며, 기본 값은 true 로 설정 -
coordination node
- Mater Node 들의 로드 밸런서 역할을 담당- Node설정이 모두 "False" 로 설정
2. Elasticsearch Cluster (Index Shard/Replica)
-
Index Shard
- 기본값 5로 설정된 5개의 Primary Shard를 구성 한다.- 초기 생성시에만 설정 가능 하며, 이후에는 수정이 불가능 하다. -
Index Replica
- Cluster 구성시 기본값 1로 설정된 복제본을 구성 한다 (단일 구성시 0)* Kibana 상으로 확인 가능
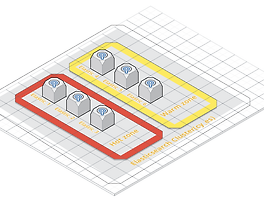
3. Elasticsearch Cluster Test

Cluster 테스트를 하기 위하여 coordinator node 를 통하여 Master/Data Node 3대로 로드 밸런싱 가능하게 구성한다.
이와 같은 구성은 추가적으로 스케일 아웃시 Data Node만 추가 하는 형태로 되어 있으며,Master Node의 Split Brain을 방지 할 수 있도록 한다.
|
hostname |
역할 |
public ip |
Elasticsearch Version |
index directory |
|
kafka-es |
coordinator |
192.168.10.190 |
6.3.1 |
/data/es |
|
kafka-es-data01 |
master/data node |
192.168.10.229 |
6.3.1 |
/data/es |
|
kafka-es-data02 |
master/data node |
192.168.10.231 |
6.3.1 |
/data/es |
|
kafka-es-data03 |
master/data node |
192.168.10.233 |
6.3.1 |
/data/es |
hostname으로 cluster 하기 위하여, host file을 추가한다.
yum repo를 이용 하여 openjdk 1.8 이상 버전으로 설치 한다.
elasticsearch Rpm 파일을 다운로드/설치 한다.
elasticsearch.yml파일을 수정하여 cluster 및 기본 설정을 구성한다.
discovery를 통하여 같은 이름인 경우 cluster를 구성 한다.
path.data 지시자에는 실제 index가 물리적으로 저장 될 공간을 추가 한다.
그리고 coodinator node로 사용 하기 위하여 node.master,node.data 지시자를 false 로 하여 실제 index가 물리적으로 저장 되지 않도록 한다.
마지막으로 discovery.zen.ping.unicast.hosts 지시자에 나머지 Node들의 정보를 추가 하여 해당 호스트에 대하여 unicast로 cluster될 수 있도록 요청 하도록 한다.
Master/Data node는 coodinator node와 다 동일 하지만 node.master,node.data 지시자를 true로 하여 data/master의 역할 을 할 수 있도록 하며,
"http.enabled: false"로 하여 해당 node들에서 rest api를 사용 하지 않도록 설정 한다.
systemctl 에 등록 및 서비스를 시작 한다.
RestAPI 로 cluster 상태를 확인 하면 아래와 같이 총 4개의 Node에 3개의 Data Node를 확인 할 수 있다.
동일한 방법으로 Master Node를 확인 하면 특정 한 Node가 Master 로 선출 된것을 확인 할 수 있다.
kibana도 동일하게 RPM파일을 다운로드 및 설치 한다(coodinator node)
Kibana 설정은 아래와 같이 0.0.0.0:5601로 바인딩 되며 coodinator node 로 Rest API 사용 하여 볼 수 있도록 한다.(coodinator node)
systemctl 에 등록 및 서비스를 시작 한다.(coodinator node)
Kibana 에 접속 후 Monitoring 기능을 활성화 하면 아래와 같이 전반적인 상태를 체크 할 수 있다

다음으로 Logstash 도 동일하게 RPM 파일로 다운로드/설치 진행 한다.(coodinator node)
간단한 테스트를 위하여 tcp 1919 포트로 들어오면 elasticsearch로 들어 오는 설정을 추가 한다.(coodinator node)
systemctl 에 등록 및 서비스를 시작 한다.(coodinator node)
nc 를 이용 하여 1919포트로 간단한 문자를 보내본다.(coodinator node)
위에서 테스트한 문자를 kibana에서 확인 할 수 있다.

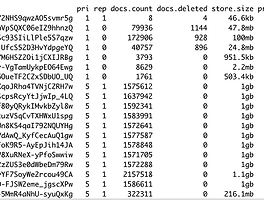
또한, 3개의 node들로 5개의 shard가 분산 되어 저장 되어 있으며 1개의 복제 shard를 확인 할 수 있다 .
여기서 kafka-es-data01 node의 elasticsearch 서비스를 잠시 중단하면 cluster status가 Yellow 상태로 변경 되며 , kafka-es-data01 node 에서 Primary shard상태에서 복제본의 Shard가 Primary shard로 변경 된다.

만약 다시 서비스를 시작 하게 되면, 다시 Shard가 분산 되어 있는 상태로 변경 된다.

반응형
'System > Elastic Stack' 카테고리의 다른 글
| Curator 를 이용한 오래된 index 자동 삭제 (0) | 2018.10.21 |
|---|---|
| Elasticsearch Hot Warm Architecture (0) | 2018.09.09 |
| Logstash Drop filter (1) | 2018.07.22 |
| Logging every shell command to elastic stack (0) | 2018.05.20 |
| Elasticsearch5, Logstash5, Kibana5 and Redis (ELKR5 Stack) install CentOS 7 (0) | 2016.12.24 |